Protokół HTTP
Projektowanie i programowanie systemów internetowych I
wykład 5 z 15

mgr inż. Krzysztof Rewak
Zakład Informatyki, Wydział Nauk Technicznych i Ekonomicznych
Collegium Witelona Uczelnia Państwowa
Blumilk sp. z o.o.
Agenda
- Komunikacja z systemem webowym
- Żądanie i odpowiedź
- Routing aplikacji webowych
- Podsumowanie
Jak rozmawiać z aplikacją webową?
HTTP (czyli Hypertext Transfer Protocol) to podstawowa metoda komunikacji między klientem a serwerem w sieci WWW. Za pomocą serii żądań i zwaracanych na nie odpowiedzi jesteśmy w stanie renderować strony internetowe, wysyłać propozycje zmian danych czy też pobierać informacje i pliki w określonych formatach.
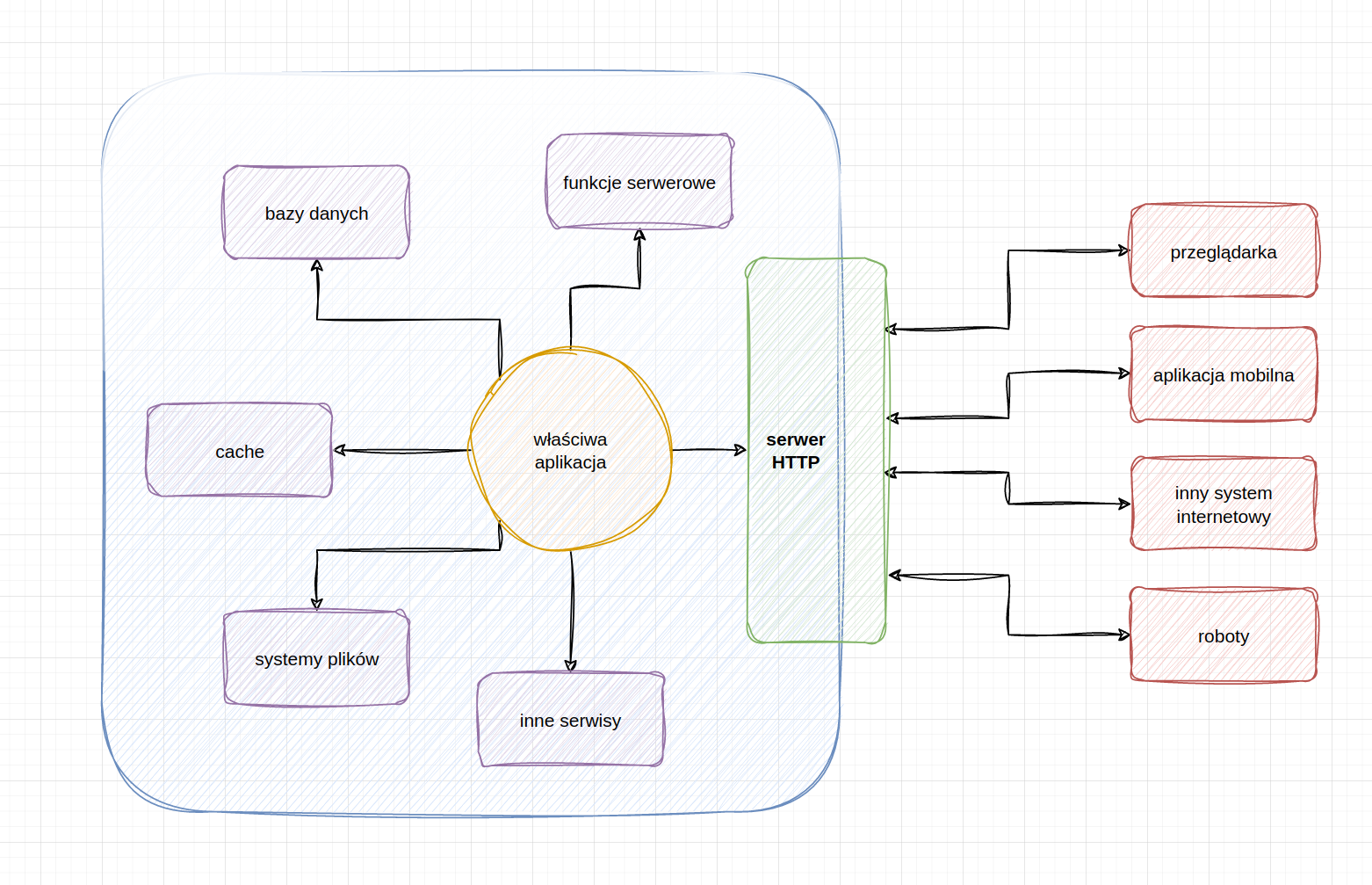
schemat budowy klasycznego systemu internetowego
(znamy to z poprzednich wykładów, ale tym razem interesuje nas tylko zielony klocek)
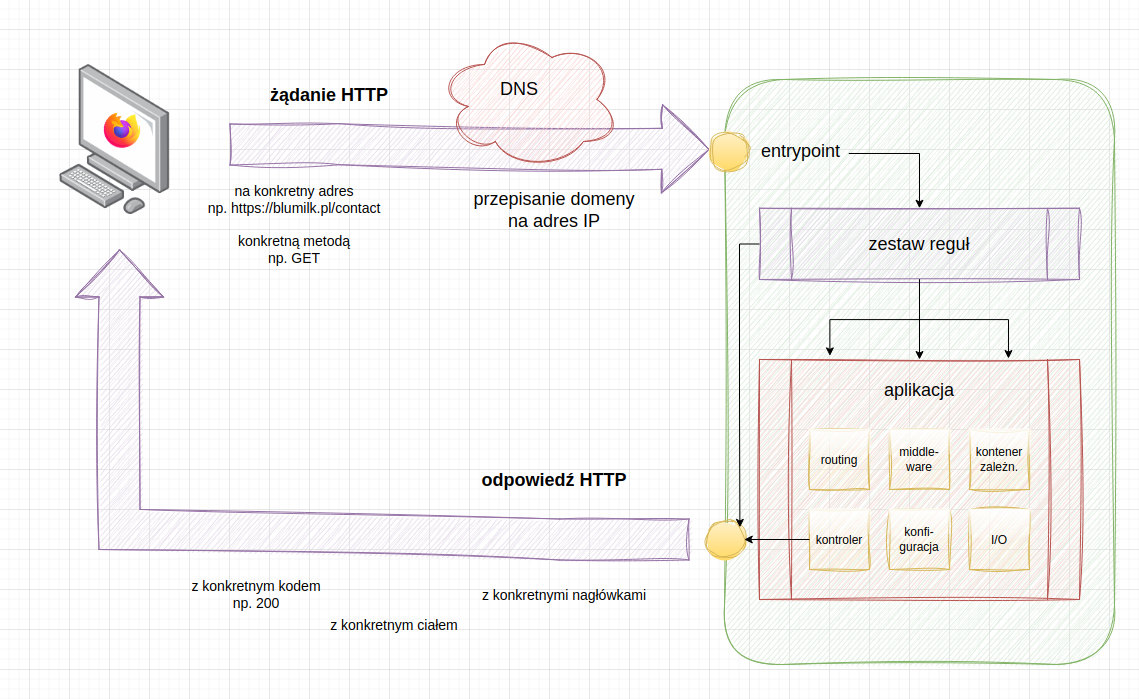
schemat wysłania żądania i odebrania odpowiedzi HTTP
Krok pierwszy: zbudowanie żądania
Żądanie HTTP (ang. HTTP request) zostaje stworzone np. poprzez przeglądarkę internetową, klienta HTTP czy bezpośrednio z kodu.
Przykładowo każde otwarcie nowej strony przez firefoksa to tak naprawdę wysłanie nowego żądania HTTP na konkretny adres z konkretną metodą, a następnie odebranie odpowiedzi, którą przeglądarka renderuje.
Krok drugi: identyfikacja DNS
Zanim żądanie trafi do odpowiedniego serwera, klient HTTP musi wiedzieć gdzie tak naprawdę ma uderzyć.
Adres internetowy (domena) tłumaczony jest na konkretny adres IP, przez który można komunikować się z serwerem HTTP. Odpowiada za to system DNS (Domain Name System), który jest jedną z podstaw internetu.
Krok trzeci: serwer HTTP
Gdy już wiemy pod jaki konkretnie adres należy zapukać, żądanie trafia na entrypoint faktycznego serwera HTTP.
Tam, zgodnie z konfiguracją serwera, może zostać wykonana dowolna akcja. Do podstawowych należą przełączenie żądania na aplikację webową, przekierowanie na inny adres, zwrócenie odpowiedzi z prośbą o hasło (tzw. basic auth) czy też odpowiedź z informacją, że plik nie istnieje.
Krok czwarty: przetworzenie żądania w odpowiedź
Na przyszłym wykładzie zgłębimy dokładniej tajniki wzorca architektonicznego MVC.
Dzisiaj musimy wiedzieć, że aplikacja webowa przyjmuje żądanie HTTP, najczęściej przerabia je na obiekt klasy
Request, przepuszcza przez zestaw funkcjonalności pochodzących z frameworka (routing, middleware itp.), a na koniec zwraca obiekt klasy Response, który zostanie przekształcony w odpowiedź HTTP.
Krok piąty: zwrócenie odpowiedzi HTTP
Na koniec odpowiedź trafia tam, skąd przybyła. Klient HTTP będzie oczekiwał odpowiedzi na każde wysłane żądanie.
(jeszcze raz) schemat wysłania żądania i odebrania odpowiedzi HTTP
Najpopularniejsze serwery HTTP
- Nginx (ok. 34% obecnie działającego internetu)
- Apache HTTP (ok. 30%)
- Cloudflare (ok. 22%)
- LiteSpeed (ok. 13%)
- IIS (ok. 5%)
- Node.js (ok. 3%)
- i inne (do 3%)
Żądanie
Serwer HTTP nasłuchuje żądań wysyłanych od różnych klientów. Najczęściej wykorzystywane są do tego porty
80 i 443, ale można to oczywiście skonfigurować zgodnie z własnymi potrzebami.
Budowa żądania
Żądanie HTTP składa się z czterech elementów:
- wiersza żądania
- dowolnej liczby nagłówków
- pustej linii
- opcjonalnego ciała z wiadomością
Budowa żądania
GET / HTTP/1.1
Host www.google.com
Accept-Language: pl
Budowa żądania
POST /issues HTTP/1.1
Host internal.local
Accept-Language: en
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
{
"title": "New issue",
"content": "Lorem ipsum"
}
Metody HTTP
Protokół HTTP definiuje kilka metod, których należy używać przy tworzeniu żądań. Najprostsze systemy będą wykorzystywały dwie podstawowe metody:
- najpopularniejsza
GETdo pobierania danych (ale zostająca w querystringu) - i druga w kolejności
POSTdo wysyłania danych
Metody HTTP
Ale bardziej zaawansowane systemy będą projektowane z myślą o bardziej semantycznie poprawnym wykorzystaniu kontekstu i implementują m. in.:
PUTdo tworzenia zasobówDELETEdo ich usuwaniaPATCHdo ich aktualizacjiOPTIONSdo technicznego sprawdzania dostępności serwera- i inne takie jak
CONNECT,HEADczyTRACE
Wstęp do REST
Zgodnie z zasadami architektury REST zarządzanie użytkownikami w systemie wystawiającym API może wyglądać tak:
GET /userswypisze listę użytkownikówPUT /userspodmieni listę użytkownikówPOST /usersdoda nowego użytkownikaDELETE /usersusunie użytkownikówGET /users/1wypisze szczegóły użytkownika o id = 1PUT /users/1podmieni dane użytkownika lub go utworzyPATCH /users/1podmieni dane użytkownikaDELETE /users/1usunie użytkownika
Budowa odpowiedzi
Odpowiedź HTTP, podobnie jak żądania, składa się z czterech elementów:
- wiersza statusu
- dowolnej liczby nagłówków
- pustej linii
- opcjonalnego ciała z wiadomością
Budowa odpowiedzi
HTTP/1.1 200 OK
HTTP/1.1 404 Not Found
Content-Type: application/json
{
"id": "5dc1e0ef-0cad-4ef6-9f88-f792bb86fb52",
"message": "Issue was not found."
}
Statusy HTTP
HTTP definiuje kody statusów odpowiedzi. Jest ich dużo, ale warto znać te podstawowe oraz ich zgrubny podział:
1xx- kody informacji zwrotnych2xx- kody sukcesu (200 OK,201 Created,204 No Content)3xx- kody przekierowań (301 Moved Permanently)4xx- kody błedów klienta (400 Bad Request,401 Unauthorized,403 Forbidden,404 Not Found,422 Unprocessable Content)5xx- kody błedów serwera (500 Internal Server Error)
System plików a routing
W systemach internetowych starszego typu często można było spotkać się z sytuacją gdzie to system plików rzutował na dostępne akcje systemu.
Przykładowo plik
contact.php zawierał w sobie cały kod związany z wyświetleniem (i obsługą!) formularza kontaktowego i można było się do niego dostać poprzez adres domena.pl/contact.php
System plików a routing
Co do zasady, a szczegółnie przy większych systemach, rozwiązanie to jest przede wszystkim niebezpieczne i trudne w utrzymaniu.
Routing
Stąd też powstała idea routingu, czyli budowania konfiguracji mówiącej co ma zostać uruchomione na wywołanie jakiego adresu. Wówczas aplikacja jest obsługiwana przez jeden plik wejściowy (entrypoint) i już wewnątrz jej uruchamiane są konkretne akcje.
Adres
domena.pl/contact nie będzie tutaj rzutował na to, że gdzieś w aplikacji istnieje plik contact.
Routing
Route::get("/random", fn(): int => rand(0, 100));
Deklaracja routingu na przykładzie Laravela.
Routing
Route::get("/", HomeController::class);
Route::get("/contact", [ContactController::class, "view"]);
Route::post("/contact", [ContactController::class, "send"]);
Route::get("/{slug}", PageController::class);
Deklaracja routingu na przykładzie Laravela.
Highlights
- aplikacje webowe bardzo mocno opierają się na komunikacji po protokole HTTP
- żądanie typu
GETnależy wykorzystywać tylko i wyłącznie do akcji, które nie zmieniają stanu aplikacji - architektura REST jest dobrym rozwiązaniem, ale rzadko bywa wdrażana w 100% zgodnie z dokumentacją
- warto dbać o kody statusów odpowiedzi HTTP, ale nie można im nigdy ufać w stu procentach
- routing przewyższa pod wieloma względami strukturę opartą o system plików
Źródła i do dalszego poczytania